


Deduplicating Large Data Volumes (LDV) in Salesforce

Bad data is the number one reason CRM implementations fail (Gartner). In addition, it is the number one reason organizations do not meet their objectives. Gartner also states: Business processes become more and more automated and the data they consume, and produce has more and more impact on customer experience. Implementing a data quality plan is paramount to ensure future success for any business. Even more so for businesses handling Large Data Volumes.
Not every deduplication solution is able to handle LDV, but Duplicate Check for Salesforce is. We are running deduplication jobs for organizations with around 20 million records on the biggest object.
We will show you what we did to make sure you are able to deduplicate millions of records in your existing database and how you deduplicate thousands of incoming leads per day in an automated way as well.
Use your scenarios wisely
It is possible to apply multiple scenarios to specific Duplicate Check features. Scenarios in itself almost always consist of multiple fields with matching methods. If you are looking to optimize the speed of deduplicating, we recommend you reevaluate the use of all scenarios and fields within scenarios. Less scenarios and less fields equal better performance.
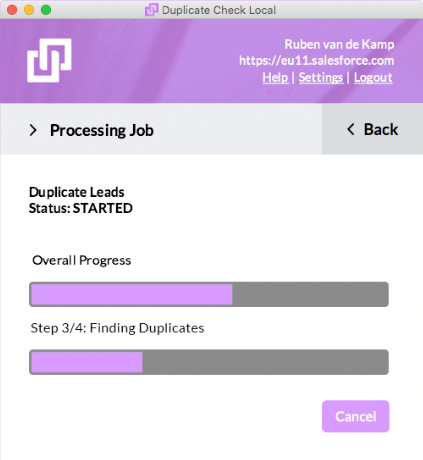
Use DC local for the big cleanup(s)
We all know the Salesforce infrastructure isn’t the fastest, especially when processing large amounts of data. And large amounts of data are exactly what we want to deduplicate. We have built a solution for this challenge with our DC local app.
With DC local, you use the processing power of your machine to process Duplicate Check jobs (deduplication of your existing database, indexing records). By nature, this will transfer Salesforce data to your machine. Since your machine is within your company network and protected by the security measures of your IT-department, your data will be safe.
Use prevention
We recommend implementing duplicate prevention for all your entry methods (manual entry, import/API bulk insert, API single insert/update, live duplicate warning), this is faster than (scheduled) jobs.
In case you choose to run scheduled jobs instead of or in addition to prevention, it is a smart idea to use the job filter to narrow down the numbers of records that need to be processed. Since DC Local has done the cleanup of your full database, it is not necessary anymore to run duplicate jobs on your full database a regular basis.
For example, if you want to deduplicate new Lead records with a job it is best to apply a ‘Job Selection’ filter like ‘Created Date’ equals ‘YESTERDAY’. This way, you will only check yesterday’s new leads for duplicates.
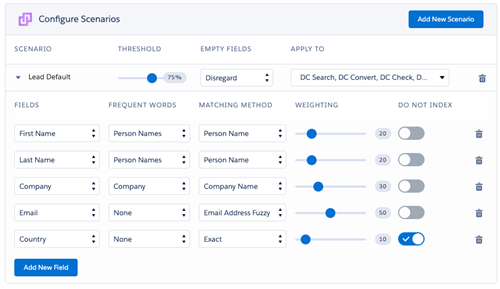
Fine tune your Search Index
The Duplicate Check Search Index is the foundation for any duplicate matching. The Search Index looks roughly like a string of values from fields you include in your scenario. Fine tune the Search Index in two ways to optimize for faster processing.
Number of records returned in index search – Duplicate Check follows two steps when finding duplicates. The first step is to gather a rough set of possible duplicates (default a maximum of 40 possible duplicates), the second step is to score all the possible duplicates according to the scenario. Records that score higher than the threshold in the scenario are listed as duplicates. The gathering of possible duplicates in the first step is a resource-intensive process. By lowering the ‘Number of records returned in index search’ you will speed up this process, possibly at the expense of finding all possible duplicates. Contact our support for advice.
Exclude fields from Search Index - Simply said, the more unique the strings in your Search Index, the faster and more accurate a job will run. It is best to exclude fields from the Search Index (not from the scenario) that have the same value across a large number of records. A good example is the field ‘Country’ for Contacts.
If you have Large Data Volumes and want to deduplicate your data, email us or schedule a call! We will work with you to ensure the solution fits your specific needs and gladly provide proof of concept.

